开始监听网页请求
指令说明
监听网页的网络数据。通常需要搭配停止监听网页请求、获取网页请求数据、网页导航-刷新等指令一起使用。网页导航-刷新会重新请求所有资源,若不使用网页导航-刷新可能无法通过获取网页请求数据指令获取数据
指令输入参数
| 输入参数 | 输入参数类型 | 说明 |
|---|---|---|
| 网页对象 | WebPage | 监听该网页的请求 |
| 资源URL | str | 当请求的url包含该值时则收集请求数据,默认收集所有请求数据 |
| 正则匹配 | bool | 是否正则匹配资源URL,默认False |
| 资源类型 | 枚举项 | 全部、XHR、Fetch、Document、Stylesheet、Image、Media、Font、Script、WebSocket、Other |
指令输出参数
无
类型定义参考
-
开始监听网页请求 - 资源URL:当请求的url包含指定的字符时则收集请求数据,默认收集所有请求数据
-
开始监听网页请求 - 资源类型:需要收集的资源类型,对应Chrome devtool中的资源类型,例如js请求、图片等
-
停止监听网页请求:当获取到请求数据后建议通过停止监听网页请求指令及时停止监听,防止数据堆积导致浏览器崩溃
-
获取网页请求数据 - 资源URL:通过url过滤请求数据,默认获取开始监听网页请求指令收集的全部数据。
获取到的网页请求数据结构如下:
[
{
"url": "",
"type": ,
"status": ,
"headers": ,
"body": "字符串",
"base64Encoded": ,
"requestId":
}
]
提示
需要先安装曲辕RPA浏览器插件
示例
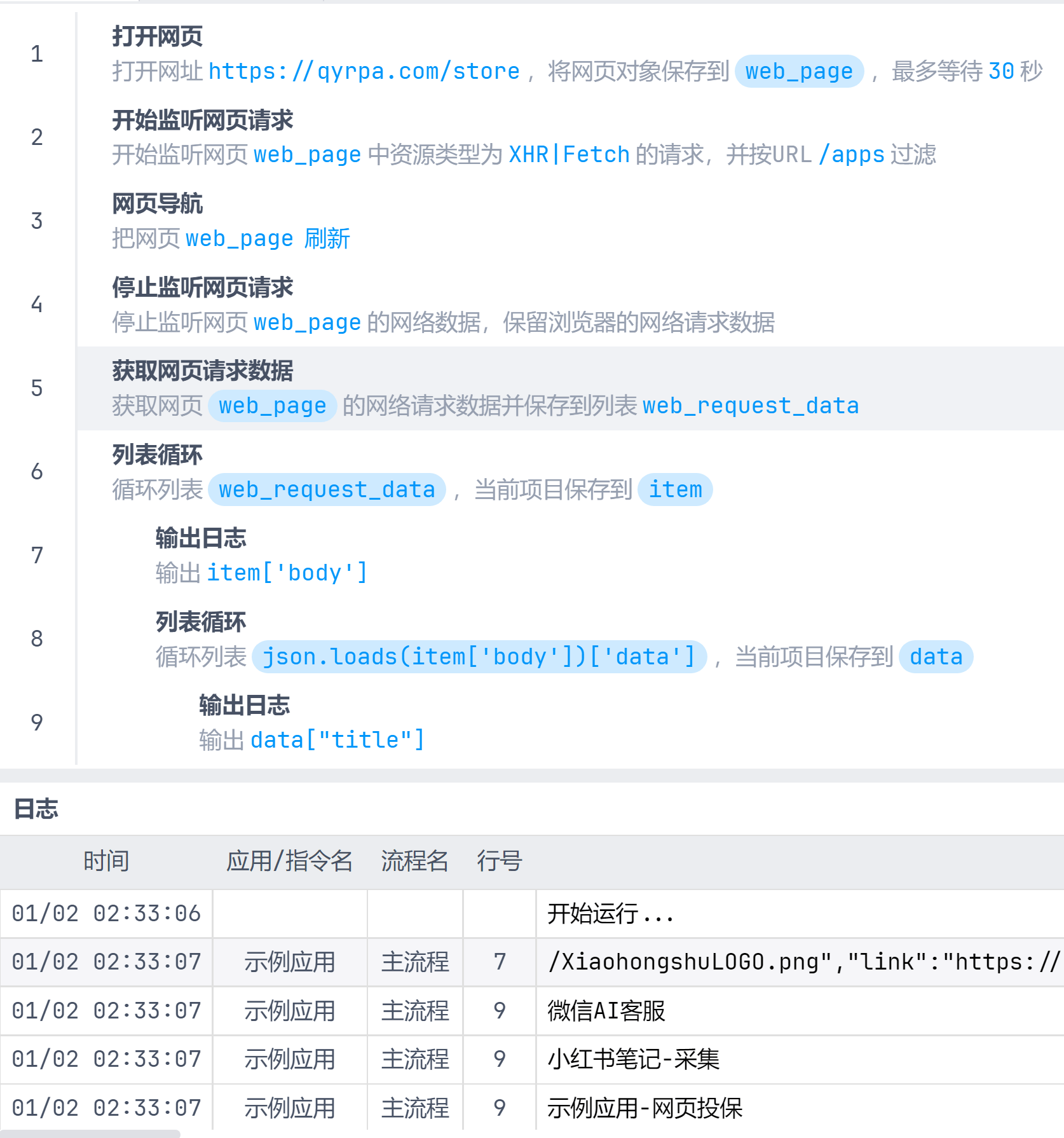
获取qyrpa的应用市场数据
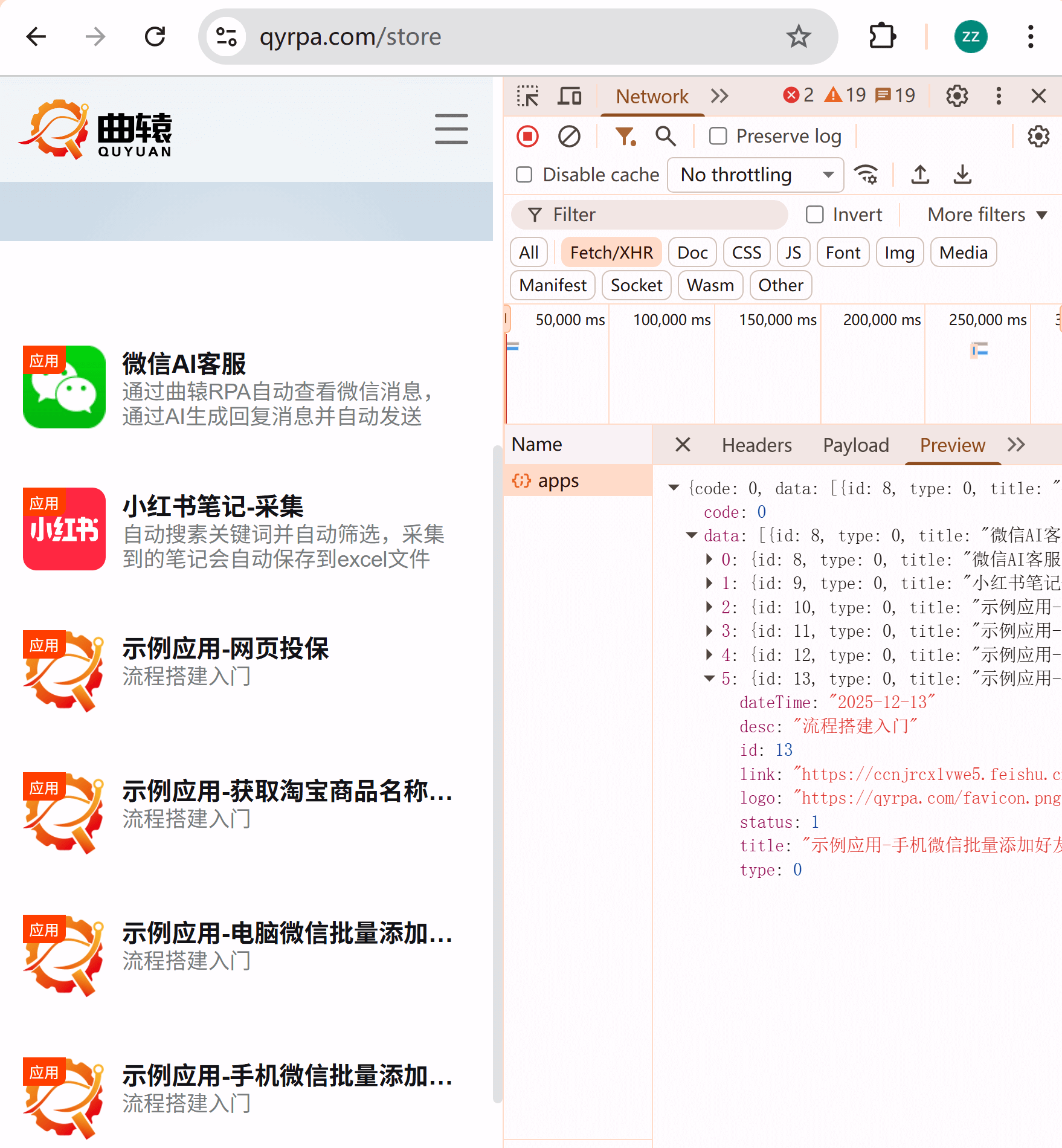 qyrpa应用市场的 /apps 接口返回的是json数据,因此需要通过json.loads解析body字符串
qyrpa应用市场的 /apps 接口返回的是json数据,因此需要通过json.loads解析body字符串
{
"code": 0,
"data": [
{
"id": 8,
"type": 0,
"title": "微信AI客服",
"status": 1,
"dateTime": "2025-06-28",
"desc": "通过曲辕RPA自动查看微信消息,通过AI生成回复消息并自动发送",
"logo": "http://static.xmzl.work/store/wchat_logo.png",
"link": "https://gitee.com/hzmosi/ai-wechat"
}
]
}
常见问题
参考 网页操作常见问题